She’s got designer chromosomes
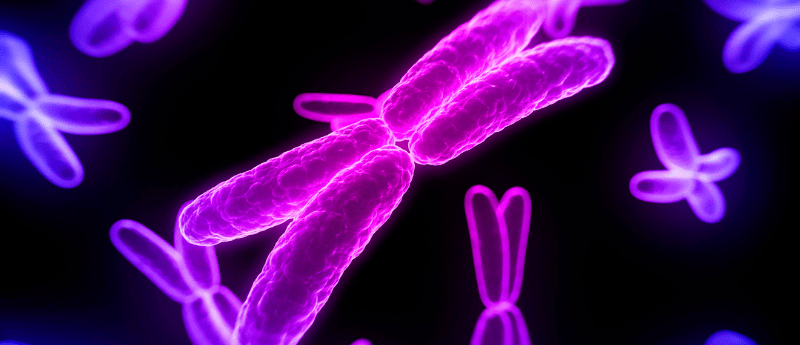
A novel machine learning (ML) model has been developed with the ability to score designer chromosome synthesis difficulty, providing guidance and potentially optimizing artificial chromosome design.
You’ve probably heard of ‘designer babies’ in the news at some point. Now we’re talking designer chromosomes. Researchers have just created an ML model that can score the difficulty of synthesizing different designer chromosomes. This kind of guidance could help optimize chromosome design and production, offering an extensive range of applications in the field of genomics.
Designer chromosomes are chromosomes that have been artificially created from scratch by scientists and enable control over a synthetic genome; providing the chance to emphasize desirable characteristics whilst removing those that are undesirable. Such artificial genome design has broad applications, spanning vaccine production and clinical research to biofuel production.
While we have breakthroughs in terms of artificially synthesizing prokaryotic genomes, as well as recent success in eukaryotic genomes, for example recreating a ‘designer’ chromosome for Brewer’s yeast, there are still numerous barriers remaining when synthesizing particular gene segments. This means that it is difficult to complete artificial chromosomes, restricting the utilization and application of artificial genome synthesis technology.
The research team from Tianjin university (China) may have now overcome these issues by developing an ML framework with the ability to assess and specify the difficulty of manufacturing a particular chromosome, which can optimize synthesis and design.
The framework was created by analyzing a dataset of a large number of chromosomes, classified into either easy- or difficult-to-synthesize. The ML framework determined six key sequence features that were associated with synthesis difficulties, comprising structural and energy information throughout DNA chemical synthesis and assembly, for example, information entropy, sequence repeats and GC content.
In response to these findings, the team then integrated these features into the framework through designing an eXtreme Gradient Boosting (XGBoost) model. The model’s chromosome synthesis difficulty prediction performance was then assessed in cooperation with a DNA synthesis company.
The model was highly accurate in predicting synthesis difficulties in this test: the AUC (area under the receiver operating characteristic curves) was 0.895 in cross-validation and 0.885 on an independent dataset of chromosome fragments.
From these results, the team presented a Synthesis difficulty Index (S-index) to quantify and interpret the difficulty level of synthesizing different prokaryotic and eukaryotic chromosomes. The S-index was discovered to accurately explicate the reasons for the varying synthesis difficulty between certain chromosome fragments, demonstrating the model’s capacity to enhance and optimize the success rate and efficacy of designer chromosome sequence synthesis and genome editing.